This exercise was using exploratory data with the use of Mean, Median, Standard Deviation and Variance from points taking of earthquake data.
 |
| This is the mean center of all the points along with the standard deviation ellipse. The mean center identifies the geographic center from the set of points. The ellipse measures the degree to which features are concentrated or dispersed around the geometric mean center. It shows that most of the earthquakes happen along the southwest of the country. |
 |
| This is the median center which identifies the location that minimizes the overall Euclidean distance to the features in the dataset. |
 |
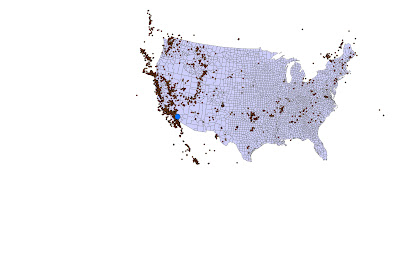
| This is a Voronoi diagram of the points in the dataset. This shows the collection of regions that divide up the plane. Each region corresponds to one of the sites, and all the points in one region are closer to the corresponding site than to any other site. |





